Why some prometheus alerts in k8s can confuse
Recently I was installing a kubernetes cluster as I usually do for my tests. However, as those machines were bare metal servers that some colleagues have recycled, we decided to keep it running and try to maintain it by ourselves.
First thing I did was a simple bot to send the alerts to a telegram channel. That was something I did not do in the past, because I do not care about monitoring as my clusters were ephemeral.
After two days, an alert started firing. This blog is my analysis of what this alert means and why I consider it not accurate, so I ended silencing it (but I would love to have an accurate alert for that situation).
The Alert
The alert in question is KubeMemoryOvercommit. It is defined in this file, and its description says:
Cluster has overcommitted memory resource requests for Pods and cannot tolerate node failure.
The rule expression for this alert is
sum(namespace_memory:kube_pod_container_resource_requests:sum{})
/
sum(kube_node_status_allocatable{resource="memory"})
>
((count(kube_node_status_allocatable{resource="memory"}) > 1) - 1)
/
count(kube_node_status_allocatable{resource="memory"})Let’s try to understand what it means.
The calculations
Looking at the different members of the equation, we can see what it means:
sum(namespace_memory:kube_pod_container_resource_requests:sum{}) = sum of memory requests in bytes for all pods in every namespacesum(kube_node_status_allocatable{resource="memory"}) = sum of memory that can be allocated to pods in every nodeernel
Dividing both, we obtain the ratio of memory allocated related with the total amount that can be. Let’s go for the second part.
count(kube_node_status_allocatable{resource="memory"}) = number of nodes that can be used to deploy pods((count(kube_node_status_allocatable{resource="memory"}) > 1) - 1) = number of nodes that can be used to deploy pods minus one, which should be at least one = remaining nodes which can allocate pods in case one is down
Dividing the latter by the former, we got a ratio of (nodes - 1)/nodes
Having the details in mind, a summary of this equation is
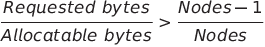
It seems very easy to understand, but it is accurate? Let’s see what it is not in the formula.
What is not considered?
I will try to summarize some of my thoughts in bullets.
For the first part, to know if pods of a node can be reallocatable or not, there are lots of different concepts to bear in mind:
- Daemonsets deploys pods per node, and this pod is meant for that node. It cannot be moved.
- NodeSelector can be used to restrict which nodes a pod can land into.
- Affinity/anti-affinity rules can also restrict where pods can be deployed
- Taints and tolerations can avoid pods to be scheduled in those nodes.
- Special hardware requirements, for example GPUs, are also restricted to some nodes of the cluster. Rules for deploying use to be based on
For the second part of the equation:
- Nodes can be different in size, so the second part of the equation is not accurate either. For example, if we have 1 nodes of 512 Gb RAM and 1 of 64 Gb RAM, if you have one half full and one empty (which you can see it will not fire the alert), if the full node is the bigger one and it goes down, you cannot reallocate the pods in the smaller, but it will be possible on the opposite direction.
Conclusion
I find it very useful to know if the platform has any risk of overcommitting the workloads if a node shuts down (either abruptly or planned). I find it particularly relevant in upgrades, where nodes usually have to be rebooted during the upgrade in a rolling process.
However, as I have shown previously, there are so many factors to consider than a simple rule based on a couple of metrics gives a false security feeling.
The only “accurate” solution that comes to my mind is if we can tell the scheduler to simulate the drain of a node and throw any issues that could be foreseen, like an extension of what is
implemented with kubectl drain --dry-run